


The Future Of Cloud-Native And Modern Application Development
25 years of perspective

I’m getting old. How do I know this? Because I started my first job when the “Internet” was an occasional destination you visited, not the place you live, work & played. Next year marks 35 years from dialing up to web-based computing. We’re making incredible progress in the tech industry connecting systems together – but we’re making things more complex too. Fortunately we’re building better technology – and I’ve never been more excited about what’s coming, so I thought I’d write a little bit about the last 25 years of distributed systems & application development and offer a call-to-action on what’s still left to be done.

The Early days of Internet Scale
The first web browser had been publicly available for less than five years by the time I joined Amazon at the start of my career back in 1997. Here’s what our systems looked like at the time:
We ran a monolithic website. We had a single web server with an “online and offline” directories. We ran on bare metal hardware running Unix key-value DBs for the catalog data and a large database on the backend to store and process orders
Networking was for systems and network engineers, who handled the specialized hardware (switches and routers) that connected the physical hosts to each other and the internet
As for data, there was a tightly controlled system that managed credit card data – akin to early network partitioning, least privilege and role-based access control (RBAC), but in a more physical sense
The first content management system and software deployment system using CVS (the version control system), Emacs, C-pre-processors and Makefiles
It’s laughably primitive now, but we had developer sandboxes, a QA/customer service environment and then pushed to that small fleet of customer facing production servers. We had the concept of atomic deployments, rollbacks. We did not have the concept of observability, synthetics or live monitoring beyond some very basic systems health checks
True story: one time I broke the Amazon.com website by pushing a bad config file, which the Apache web server picked up, and then froze all the processes, requiring a hard, physical reboot of the frontend web server fleet. I learned a lot about bounds/input checking that day.

Overall, the bottlenecks became obvious quickly: the presentation layer, business logic and data were all intermingled, which meant to add functionality we often had to be an expert in all things – systems administration, database engineering, programming. And to be honest, most of us were still using big converted rooms in old buildings, not even purpose-built data centers.
A Manifesto for Distributed Computing
It wasn’t long before we ran out of capacity on the biggest servers made at the time by DEC (Digital Equipment Corporation, our Unix server vendor). We needed scale, which meant a fleet of front-end web servers, which meant we needed to build a distributed system.
To address this at Amazon, several senior engineers wrote a “Distributed Computing Manifesto.” The objective was to separate the presentation layer, business logic and data, while ensuring that reliability, scale, performance and security met an incredibly high bar and kept costs under control. This removed bottlenecks to software development by scaling our monolith into what we would now call a service-oriented architecture. Do these concepts and problems sound familiar to you even now? Again, this is before virtual machines (VMs), and long before containers, Docker & Kubernetes. Before we get to that, let me briefly talk about Distributed Systems.
Computing at Massive Scale – Why Is this Hard?
Why was this a challenge? Why did engineers feel compelled to write a manifesto? Well, while programming patterns and abstractions in both hardware and software have solved lots of problem, one we’ve not solved is distributed systems.
Service-oriented architectures can actually make things extraordinarily more complex with dozens of services talking to each other – and absent observability tools and dashboards – it’s hard to know if you are experiencing a problem in networking, databases, or something else.
Distributed Systems are about designing for failure. And systems fail all the time. Managing and recovering from these incidents requires thinking deeply about those failure modes. There’s even principles in computer science, including the CAP theorem, dedicated describing the limitations of systems that design for failure (i.e. you can’t be infinitely performant, consistent and available - there are tradeoffs).
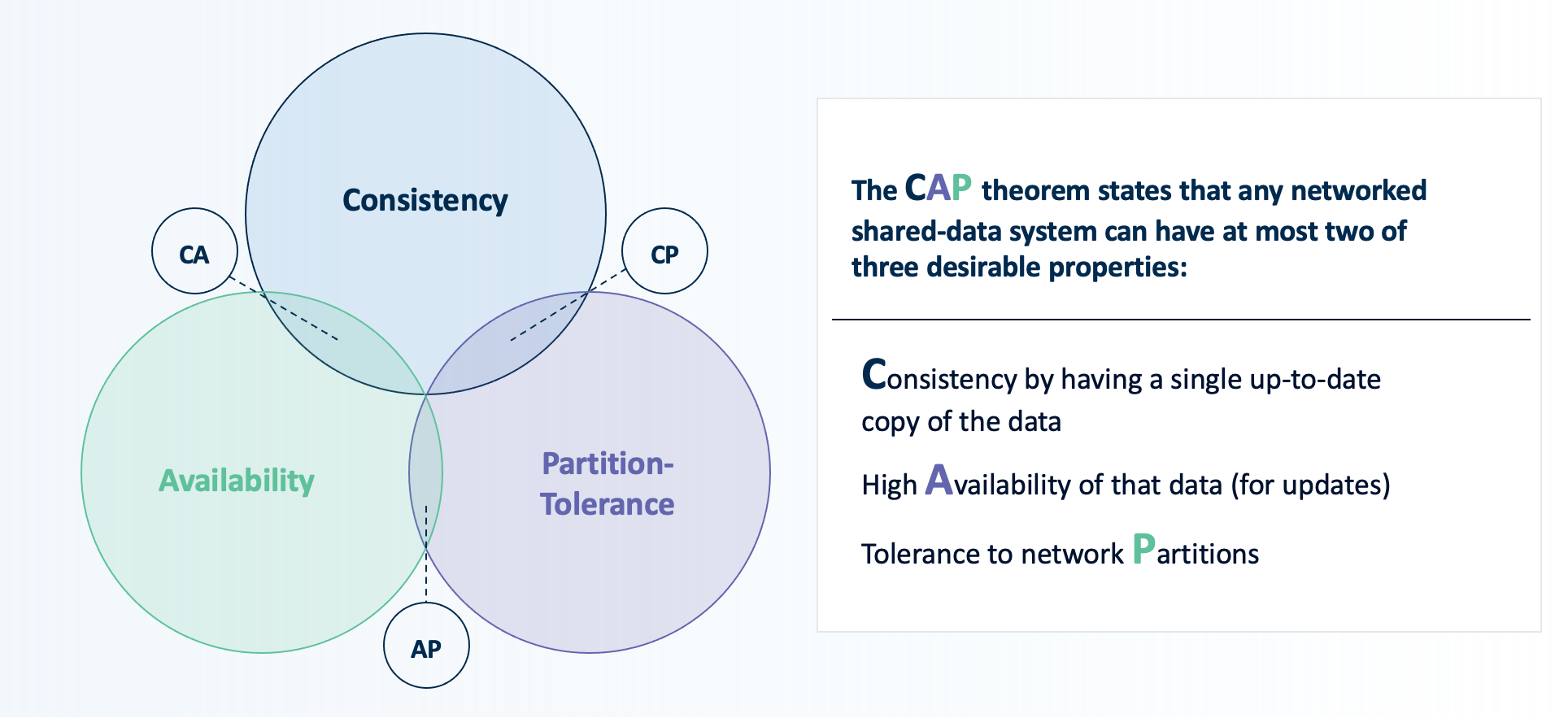
Alright – but you didn’t come here for a computer science lecture, so I’m not going to go into distributed consensus protocols in depth. I think it might be useful to back up a bit and cover how we got here.
A brief timeline of distributed systems

In the Beginning, there was ARPANet (1969)
The pre-cursor to the modern internet - ARPANet - which stands for Advanced Research Projects Agency Network. This emerged from the government and military’s interest in secure communications, information sharing. It included the then novel ability to remove single point of failure if an HQ went down. Of course it was connected initially over dedicated phone lines.

While I’m not quite as old as the ARPAnet, I did dial into bulletin-board-systems (BBS) using my 300 baud modem to download hints and run-throughs for Infocom text-based adventures.
This concept of being able to remove a single point of failure is really one of the core concepts of distributed systems, but it’s also what makes it hard, as I mentioned.
Which Becomes the Internet (1989)
Arpanet ended in 1989, which is not-coincidentally when internet access was officially offered commercially. We’ve had more innovation in this space in the last 20 years than in all previous decades combined, why? I’d argue it goes back to Tim Berners-Lee inventing the “world-wide-web” in 1989 and the introduction of the first web browser available to the public in 1993 (Mosaic)
Virtualization Emerges (1999)
In 1999, where VMware presents its first product, Workstation 1.0, at DEMO 1999. It might seem hard to believe now, but the Wall Street Journal declared:
“VMware Brings Freedom of Choice to Your Desktop… Programmers around the world delight in the product, which allows a user to run multiple operating systems as virtual machines, all on a single PC”
But this alone didn’t revolutionize the development of software – business apps were written and distributed as binaries and this was focused on the desktop. It was still revolutionary, and really not that long ago in the history of technology time.
… And Evolves Into the Hypervisor (2002)
But it wasn’t until 2002 when VMware released the ESX Server, it’s first hypervisor, and over on the Linux side the Xen hypervisor was released - that we really begin to see the emergence of the pattern that I’d argue we’re still continuing today in how applications are built and clusters of resources are managed.

If you’re not deep in virtualization, responsibilities of the hypervisor include memory management and CPU scheduling of all virtual machines ("domains"), and for launching the most privileged domain ("dom0") - the only virtual machine which by default has direct access to hardware. From the dom0 the hypervisor can be managed and unprivileged domains ("domU") can be launched. By consolidating multiple servers onto fewer physical devices, virtualization streamlines IT administration, helps organizations cut costs and provides a layer of abstraction from the physical hardware that frees application developers, boosting their productivity.
Remember, at this point, we’re operating in individual company data centers and most server-based applications aren’t built to be immediately virtualized. They often expect direct access to the hardware or contain architecture-specific bindings.
Introducing the Cloud (2006)
I’d argue that virtualization was a key development made cloud companies like Amazon Web Services (AWS) possible. One fun fact is that AWS actually launched S3 – the simple storage service - before it launched the Elastic Compute Cloud (EC2) which let you “rent servers by the hour”


Behind the scenes at AWS, EC2 was running on a version of the Xen hypervisor. But if you were a developer you generally didn’t need to know that – AWS abstracted that away from you, and modern “cloud-native” applications were built with this in mind.
In 2009 that AWS launched VPC (virtual private networking) - which provided advanced networking and logical isolation features. It’s also in 2009 when AWS launched RDS, their first Relational Database Service. Obviously since then AWS, and others like Microsoft Azure, Google Cloud, Oracle Cloud Infrastructure (OCI) have abstracted away much of the underlying compute, storage, database and networking layer, added streaming data processing and data warehousing services, and so on. This “infrastructure as a service” (or IaaS) comes at and creates an inflection point.
I’d argue that distributed systems at scale were fundamentally not possible until the underlying infrastructure was capable, the abstraction layers in place, we had ready access to commodity hardware in the cloud, and a use case beyond the military – we needed web-scale companies before we had broad-based use of distributed systems for commercial interests.
But this scale introduces a new problem. These web scale companies – like Amazon (the e-commerce/retail side), but also Netflix, Google (search), Twitter, Yelp, etc– find themselves building and operating fault-tolerant and elastic distributed systems – which means huge pools of VMs and other resources.
Building Elastic Distributed Systems (2009)
One of the innovations to come out at this time was Apache Mesos. In case you don’t remember, Mesos was one of the earliest of the modern distributed systems focusing on abstracting physical data center resources into a pool. It had pluggable isolation for CPU, memory, disk, ports, GPU, and modules for custom resource isolation; and pluggable scheduling.
In Mesos-terms, “frameworks” (the distributed application or service) leverage Mesos to manage & allocate resources, tasks represent work units to be executed, and executors handle execution of tasks on agent nodes within a Mesos cluster. This separation allows for efficient & flexible resource management and task execution across a distributed environment.
Mesos was adopted at Twitter and Twitter engineers actively contributed to Mesos and authored Aurora (the scheduler). A host of the Apache projects that emerge after this ran or run on top of Mesos including Hadoop & Spark. Mesos started as machine (physical/VM) cluster manager and later added Docker/container support.

The Rise of Containers (2013)
So, we’ve gone from a few machines connected on phone lines, to the commercial internet, to desktop and then hypervisor-based virtualization, to limitless scale in the cloud. We’ve got these complex distributed systems operating at scale and elastically. We’ve abstracted some of the undifferentiated heavy lifting from our application developers. What’s next? Operating-system (OS) level virtualization.

Docker did not invent containers, but it made the technology accessible through an open source tool and reusable images.
Now you’re running applications inside multiple isolated user space instances, the containers, to which only parts of the kernel resources are allocated. Much like virtualization let you carve up one physical host into smaller virtual machines, containerization lets you carve up the machines even more efficiently, because you’re re-using the OS and other shared components. Containers also start & stop faster than VMs, tend to be more portable across architectures (x86/ARM), and easier to scale up & down. Containers further delivers on the promise of making it easy to break complex monolithic applications into smaller, modular microservices.
At least in theory.
Enter Kubernetes (2014)
So now we have these elastic, micro-services-based, containerized applications, running at scale, well that means we need something to orchestrate them. Does this sound familiar? We’re seeing the same thing happen every time we hit the next “order of magnitude” of scale with any application development pattern or environment.
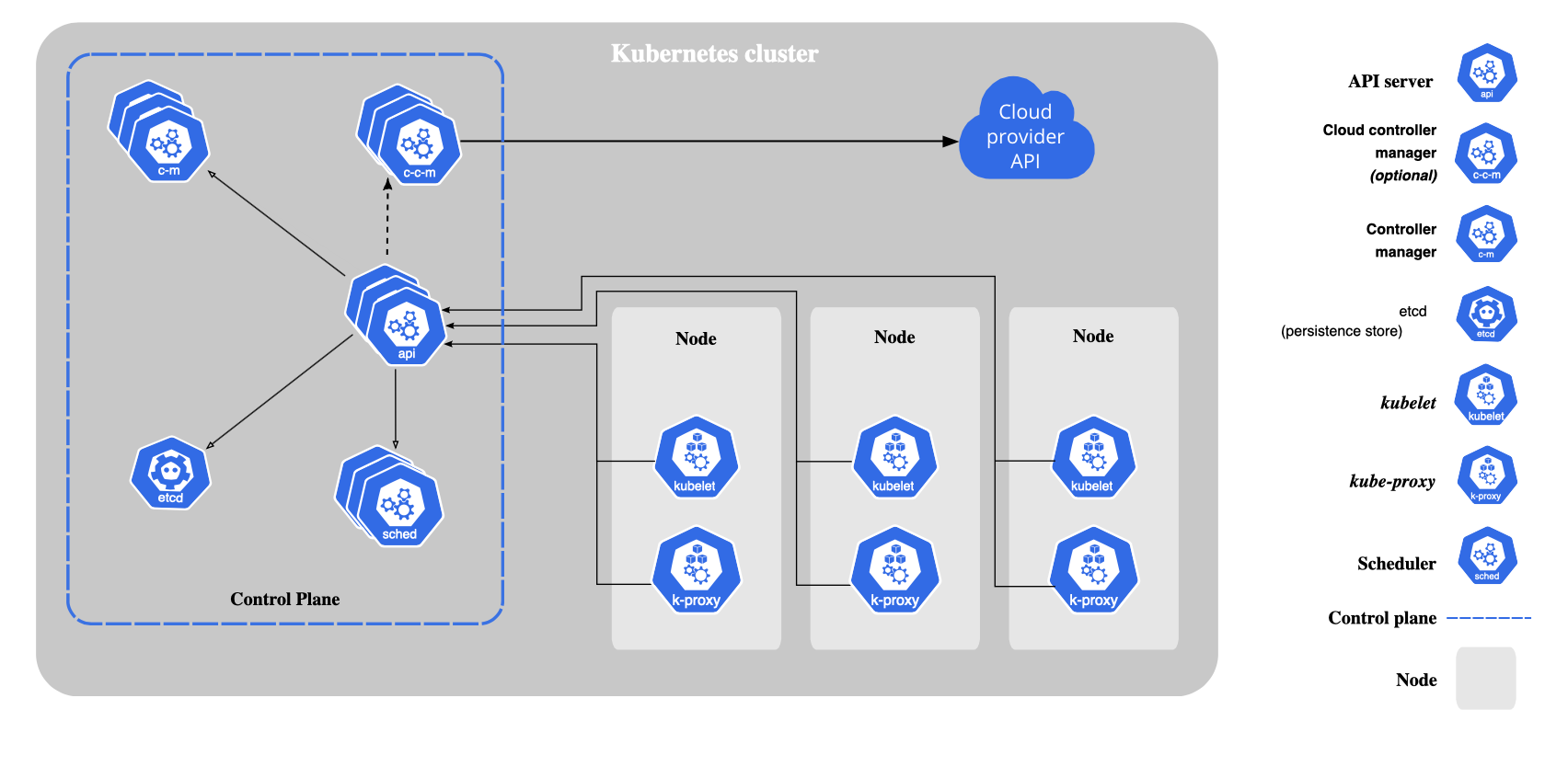
Kubernetes building blocks ("primitives") provide mechanisms that deploy, maintain, and scale applications based on CPU, memory[32] or custom metrics – at a finer scale and more extensibly than doing this purely in VMs or managing the raw containers yourself. Kubernetes solves problems like deploying your applications into the right containers, autoscaling, efficient bin packing, decommissioning containers that aren’t in-use, health monitoring and more.
One of the reasons I think Kubernetes has taken off so quickly is that it’s highly extensible and built on a set of primitives/building blocks that has allowed there to be a large community and ecosystem that’s grown around it. Between this and Docker’s success there’s a lesson here for anyone who wants to launch the next tech innovation that revolutionizes the tech industry.
But remember how I said distributed systems are hard? Kubernetes doesn’t fix that. When you look at the architecture diagram above you’ll see the inherent complexity and possibilities of numerous failure modes.
Container Management (2014-2019)
So we need to manage those containers. Like most distributed systems, Kubernetes has two components - the control plane and worker nodes. The control plane is responsible for managing the entire cluster infrastructure and the workloads running on it. The nodes act as the workhorses that run the customer applications packaged as containers.
Way back in 2014, around the same time as the launch of Kubernetes, AWS launched their Elastic Container Service, which is a service widely-used by customers who either adopted it before Kubernetes became broadly used outside of Google, and those who are “neck-deep” in the AWS ecosystem and appreciate that ECS integrates natively with so many other AWS services.
Starting in 2015 with GKE, you have the first managed Kubernetes service, with a cloud provider owning and managed the control plane, which is the critical part of the cluster infrastructure. Since the worker nodes are essentially a set of virtual machines, they have always been accessible to users. This is fundamentally just a managed environment for deploying, managing, and scaling your containerized applications. To serve a very similar purpose, and because their customers asked, Amazon introduced EKS a few years later. Similarly Azure introduced AKS and Oracle launched Container Engine for Kubernetes (OKE).

For customers operating on multiple clouds, on-prem, in hybrid environments – and who have more specific needs like operating at the edge- you also have services like Tanzu from VMWare1 and Rancher’s k3s product – which is a lightweight certified Kubernetes distribution.
And now we’re done (2023)

We’ve now reached the point of making it easy to break complex monolithic applications into smaller, modular microservices – fully encapsulated into one neat container and running on near limitless cloud or cloud-like infrastructure, mostly abstracted away from the average developer. We’re ready for the broad-based use of distributed systems for commercial interests. We have these elastic, micro-services-based, containerized applications running at scale, and we need something to orchestrate them. And we’re now operating on multiple clouds, on-prem, in hybrid environments – we’re able to address more specific needs like operating at the edge.
But there’s tons left to do…
So What’s Next?
As I take a closer look at the big challenges we need to tackle I've pinpointed five key areas, where I believe entrepreneurial & innovative technologists can really make their mark: Distributed data stores, service discovery, databases, storage and security.

Etcd
Etcd is the distributed key-value store that is commonly used for configuration management and coordination among distributed systems in a cloud-native environment. A lot of folks love to talk about how complex and frustrating etcd is. It’s more just the fact that etcd is a distributed system, and distributed systems are inherently complex and frustrating as I’ve said in this article. The opportunity is to make this self-healing and largely invisible for customers.
Service Discovery
With thousands of micro-services managing service discovery and appropriately designing and segmenting our network, we still require specialized knowledge. There’s a variety of service meshes – which aim to solve the traffic management, security, and observability challenges introduced by microservices and distributed architecture. And of course there’s still the interaction of the physical network. Likely there’s more than one solution to this problem – because it crosses so many domains – but interoperability will be key, not sloughing off the complexity onto some “out-of-site, out-of-mind” platform operations teams like we see now.
Databases
Most folks are still running databases the old way. Using a database as a thinly-managed service from one of the cloud providers or vendors. This only makes some of these problems go away, but we need automated deployment, fine-grained resource allocation and efficient use of resources and portability that we see elsewhere in the container space.
Storage
Container-attached storage is in its infancy. We need to to take all the innovations we’ve seen in cloud storage – especially around object and block storage being near-infinite, and separating IOPS from volume size, and bring them fully down into the container world’s level of abstraction.
Security
This is harder than ever. It’s not feasible just to have perimeter security or lock down every port. Traditional security tools were not designed to monitor running containers. Namespaces are not a security boundary. I see the next frontier of container-aware security focused less on the specific infrastructure and more about the end-to-end application operating on many underlying resources. Included in this focus will be the need to fully provide a secure end-to-end “supply chain”for modern applications. Here there are many entrants, but VMware Tanzu and Stacklok stand out (not coincidentally, both created by Craig McLuckie, the co-creator of Kubernetes).
My Challenge To You
Failure modes are more complex – remember that story I told you about Amazon’s early foray into service oriented architecture and how it actually made diagnosing web site failures and grey-outages harder? That’s where we are right now.
You’ve got containers running on VMs interacting with serverless functions and databases as a service (sometimes many databases – NOSQL, SQL, etc). How do we go beyond logs, metrics and traces and build systems that learn and adapt to prevent failures, auto-healing rather than requiring the same kind of manual intervention (re-deploy, restart) that we’ve been doing for 25 years?
The composable web or computing at the edge – when I think of technologies like Web Assembly (WASM) I don’t even think we’ve begun to contemplate how it changes all the things about application development when it’s distributed orders of magnitude further than it is now.
Even after 25 years in this business I’m excited about the future and feel like we’re just getting started. I’ve always been impressed by the level of entrepreneurship and innovation coming out of the technology industry. There’s endless opportunity - whether it’s consumer or business apps, or platforms that serve developers. You just need to go out there and seize it.

Disclaimer: VMware is my current employer, although as noted this blog post does not represent their views
Excellent article! Understanding the historical progression of software/systems architecture through virtual machines, cloud computing, Docker, and Kubernetes is crucial in understanding today's multi-cloud environment.
Until companies from IaaS providers to software development (db or application) houses really come to grips with supply chain risk management and full asset inventories that can be ingested and interrogated with open standards-based tools...security has a long way to go. Push a vendor to truly meet NIST 800-53 Rev 5 SR family of controls and watch their legal and IP stewards go apoplectic.