
Building a Culture of Operational Excellence
Lessons from the Crowdstrike Outage & a Decade at Amazon

The recent Crowdstrike outage is a reminder of the critical role that operational excellence plays in cybersecurity. In today’s hyper-connected world, where even a brief service interruption can cascade into a major crisis, it’s not just the technical failures that matter – it’s the operational practices behind them that often determine whether an issue becomes a minor hiccup or a full-blown catastrophe.
This incident wasn’t merely a failure of technology; it was a failure of deeply ingrained operational practices. Drawing on lessons from over a decade at Amazon and AWS, where I had the privilege of working with some of the largest-scale live systems in existence, I want to explore how organizations can build a culture that not only prevents such failures but also shows resilience in the face of these inevitable challenges for technology service companies.
We’re putting these same practices to work at Upwind, where we’re building a culture of operational excellence from the ground up. By embedding these principles into our daily operations, we’re ensuring that our systems are resilient, our teams are prepared, and our customers are protected.
Root Cause: Beyond the Technical Failure
Crowdstrike’s incident had a clear technical root cause, but stopping there misses the broader point. According to their detailed root cause analysis, the failure occurred due to a “mismatch in the number of input parameters provided to a content interpreter within their Falcon sensor software.” Specifically, their new IPC Template Type, introduced in February 2024, defined 21 input parameter fields. However, the integration code that invoked the content interpreter with Channel File 291’s template instances supplied only 20 input values. This mismatch evaded multiple layers of build validation and testing, leading to a situation where the system crashed when the 21st input parameter was expected but not provided. [Source: https://www.crowdstrike.com/wp-content/uploads/2024/08/Channel-File-291-Incident-Root-Cause-Analysis-08.06.2024.pdf]
While the immediate technical cause was identified, the deeper issue lies in the operational processes – or lack thereof – that allowed this mismatch to go unnoticed through several layers of testing and deployment. It’s easy to say, “We found the bug, we’ll fix it, and we’ll do better testing next time.” But the real question is, why did this issue slip through the cracks in the first place? Operational excellence isn’t just about resolving issues when they arise – it’s about creating systems and processes that make these failures less likely to occur in the first place.
In my time at Amazon, and especially the latter years at AWS, operational excellence was woven into the very fabric of the company. It wasn’t just a set of practices or guidelines; it was a mindset that permeated every decision and action. This mindset starts with recognizing that while technology can and will fail, the mechanisms surrounding it shouldn’t. The key is to create an environment where failures are anticipated, prepared for, and quickly contained.
We’re putting these same practices to work at Upwind, where we’re building a culture of operational excellence from the ground up. By embedding these principles into our daily operations, we’re ensuring that our systems are resilient, our teams are prepared, and our customers are protected.
So, how can organizations prevent incidents like the Crowdstrike outage from occurring in the future? It starts with a commitment to operational excellence across every level of the organization. With that in mind, here are some key practices that, when implemented consistently, can help build a more resilient and robust operational framework:
Key Practices for Operational Excellence
Incident Management: At Amazon, every team had a designated incident manager and a clear escalation path ready before an event occurred. This wasn’t just a theoretical exercise—it was a day-to-day reality. The incident manager was responsible for not only coordinating the resolution but also for communicating status and next steps to all stakeholders. Even the smallest teams needed central coordination to ensure that incidents were handled swiftly and effectively. I remember one instance where a potential issue with our cloud infrastructure was detected very late in the evening on a Friday, where staff had mostly gone home for the weekend. Thanks to the clear escalation path and the preparedness of the incident manager, we were able to address the issue before it escalated, minimizing downtime and customer impact.
Communication During Crises: One of the most overlooked aspects of incident management is communication. When primary systems go down, how do you ensure that everyone stays informed? At Amazon, we developed robust communication plans that included alternative channels—like phone trees or text messaging—to keep everyone in the loop. This wasn’t just about keeping engineers informed; it was about ensuring that customer service, sales, and PR teams were all on the same page, ready to respond to customer concerns. During one major outage in EC2, our ability to maintain clear and consistent communication across the organization meant that we could manage customer expectations effectively and reduce the overall impact on our reputation, even as it took us nearly ½ a day to resolve the underlying issue and get everyone back and healthy.
Event Classification Systems: Not all incidents are created equal, and it’s crucial to have a clear, objective system for classifying them. At AWS, we had a well-defined classification system that helped us determine what was critical, high, medium, or low priority. This ensured that the most severe issues were always addressed first, while lower-priority items didn’t create unnecessary noise or churn. In one particular case, an issue that initially seemed minor was quickly escalated due to its potential impact on a critical customer-facing service, allowing us to prioritize resources and prevent a more significant failure.
Root Cause Analysis and Correction of Errors: After an issue was resolved, the work wasn’t over. At Amazon, we conducted thorough root cause analyses and created Correction of Errors (CoE) documents. These weren’t just check-the-box exercises; they were detailed investigations that went beyond the technical issue to uncover the underlying causes. The goal was to prevent the same problem from happening again, not just in that team but across the entire organization. I recall a situation where a seemingly simple bug fix in S3 revealed deeper issues with our deployment processes across the board. By addressing these root causes, we were able to improve our overall system resilience significantly.
Simulations and Preparedness: Regular tabletop exercises and game day simulations were a cornerstone of our operational preparedness. These exercises weren’t just about practicing our response; they were about finding weaknesses in our systems and processes before they could be exploited by real-world events. At Amazon, these simulations helped us prepare for everything from large-scale outages to smaller, more contained incidents, ensuring that we were always ready for the unexpected. For example, one simulation revealed a critical gap in our backup/recovery systems for our RDS service data-plane, which we were able to address before it became a real issue during a later incident.
Cross-Functional Coordination: Effective incident response isn’t just the responsibility of engineering teams. At Amazon, we made sure that incident response involved a coordinated, cross-functional effort that included customer service, sales, and PR teams. This ensured that any potential impacts on customers, prospects, and the brand were addressed swiftly and effectively. Although major incidents were rare at AWS, when they occurred the blast radius was large given AWS’ huge user base. So this cross-functional coordination allowed us to not only resolve the technical issue quickly but also manage customer communications in a way that maintained trust and minimized churn.
The 5 Whys Methodology: Digging Deep for True Root Cause Analysis
One of the most powerful tools in our arsenal was the "5 Whys" methodology—a simple yet profound approach to root cause analysis used to drill down into the underlying cause of a problem by repeatedly asking the question "Why?" until the fundamental issue is identified.
This technique was originally developed by Toyota as part of its lean manufacturing process but has since been widely adopted across various industries, including tech and engineering.
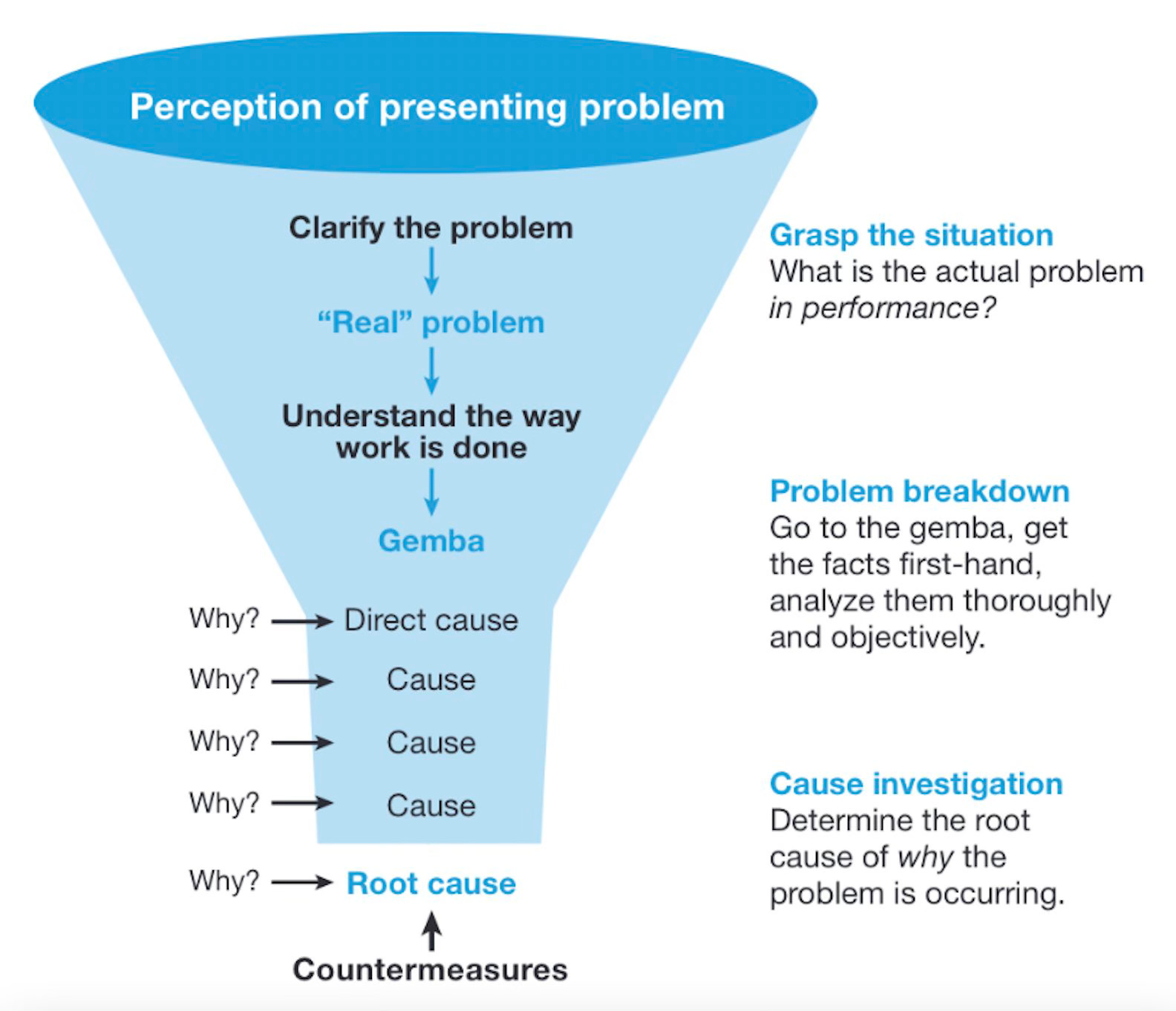
When an incident occurs, it's easy to stop at the surface level by identifying the immediate technical issue—e.g., a server failure or a coding error—and move on. However, the "5 Whys" approach digs deeper to uncover the systemic issues that allowed the problem to occur in the first place. This process often reveals organizational shortcomings, such as gaps in communication, flawed processes, or cultural issues, that need to be addressed to prevent recurrence.
Example of the "5 Whys" in Action:
Let’s say a critical system went down due to a database failure.
Why did the system go down?
Because the database became unresponsive.
Why did the database become unresponsive?
Because it ran out of memory.
Why did it run out of memory?
Because a query was executed that consumed all available memory.
Why was such a memory-intensive query executed?
Because the query was not optimized, and no limit was set on the memory it could use.
Why was the query not optimized, and why were there no memory limits?
Because the development team lacked proper training on database optimization, and there were no guidelines or automated checks in place to enforce memory limits.
In every major outage at Amazon, part of the CoE (correction of errors) process involved the 5 whys. Instead of stopping at the first cause you found, you asked "Why?" five or so times to drill down to the fundamental issue. This methodology helped us uncover not just the immediate technical problem, but the deeper, systemic issues that allowed it to happen in the first place.
Applying the 5 Whys to the Crowdstrike Incident
Let’s take a closer look at how the "5 Whys" could have been applied to the Crowdstrike incident:
Why did the system crash?
Because the content interpreter attempted to access an out-of-bounds memory location.
Why did it access an out-of-bounds memory location?
Because it expected 21 input parameters, but only 20 were provided.
Why were only 20 input parameters provided?
Because the integration code that invoked the content interpreter was only set up to handle 20 inputs.
Why was the integration code only set up for 20 inputs?
Because the new IPC Template Type, introduced in February 2024, defined 21 input fields, but the testing processes did not include a scenario where the 21st input field was required.
Why did the testing processes not include this scenario?
Because the test cases were based on previous template instances that used wildcard matching criteria, which did not trigger the out-of-bounds issue.
By the time we reach the fifth "Why," it’s clear that the true root cause isn’t just a technical oversight – it’s a gap in the testing and validation processes. Addressing this root cause would involve more than just fixing the immediate issue; it would require revising the entire testing framework to ensure that all potential edge cases are considered.
You can also apply additional questions beyond the 5 whys that get to the root cause of why a particular outage lasted longer or had more impact than it otherwise could have. This helps you consider action items that will reduce the impact of any outage next time. Examples of these questions include:
Why did this outage take so long to detect?
What could be done to cut the detection time in half?
Why did it take so much effort to remediate this issue?
What could be done to automate remediation in the future?
This approach is far superior to simply concluding, “We should have done better testing.” It forces teams to think critically about the processes and cultural factors that contribute to failures, or contribute to failures being excessively impactful. This process leads to more meaningful and lasting improvements. At Amazon, applying the "5 Whys" not only helped us fix technical issues but also drove continuous improvements in our processes, making our systems more resilient over time.
Building a Culture of Continuous Improvement
At Amazon, operational readiness reviews (ORRs) were a critical checkpoint before any new product or major feature went live. These reviews weren’t just about checking off boxes—they were a rigorous examination of whether the service was truly ready for prime time. If a product didn’t pass the ORR, it didn’t launch. Period. I remember a time when a high-profile product was delayed because it failed to meet our ORR standards. While this was a tough decision, it ultimately protected our customers and preserved the integrity of our brand.

But operational excellence doesn’t stop at the launch. It’s an ongoing commitment that requires continuous assessment and reinforcement. That’s where cross-organization ops meetings come in. These meetings brought together a diverse group of participants, from VPs to junior engineers, to review recent incidents, share lessons learned, and align on strategies for improving operational practices across the company. These meetings weren’t just about leadership giving directives—they were about fostering a culture where operational excellence was a shared responsibility, ingrained in every team and every individual.
Conclusion
Operational excellence isn’t a one-time effort; it’s an ongoing journey and a direct reflection of your culture. The Crowdstrike outage is a clear reminder that even the most advanced technology can falter if the operational practices supporting it aren’t solid. By embracing practices like the "5 Whys" methodology, conducting thorough root cause analyses, and cultivating a culture of continuous improvement, organizations can build systems that are not only resilient but also capable of preventing the next big outage.
Ultimately, it’s about more than just fixing problems — it’s about creating an environment where failures are rare, and when they do occur, they lead to meaningful, systemic improvements. That’s the true essence of operational excellence, and it’s a lesson I’ve carried with me from my years at Amazon into every challenge I’ve faced since, including my work at Upwind.
This "why" could go in many different ways other than testing depending on the question you ask and the rigor you apply.
"
Why was the integration code only set up for 20 inputs?
Because the new IPC Template Type, introduced in February 2024, defined 21 input fields, but the testing processes did not include a scenario where the 21st input field was required.
"
Strictly speaking, the respomse to the specific question shouldn't really talk about testing. Next question would be "why did it define 21 fields". Perhaps a question like "why was this breaking change allowed to make its way into prodiction?" would reveal the issue with the test much sooner.
We do need branches of whys that focus on different aspects.
With CrowdStruck, we have several roots to start with:
root 1: why was this able to make it into prod undetecred?
root 2: why did it take so long to recover?
root 3: why did the breaking change exist in the first place?
And perhaps different groups would ask different questions depending on their context.
Microsoft might ask their own questions..
root 1: why was a vendor defect able to cause our severe service outage?
Ask the right questions starting in different contexts and stick to those contexts to get the most benefit.